
作者:小满zs
链接:https://juejin.cn/user/2463384809252397/posts
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Vue
为什么Vue3要重写双向绑定?
答:Vue2的实现方式(Object.defineProperty的getter / setters)对数组的处理不友好。Vue3使用Proxy+Object.defineProperty进行优化。
关于Vue3支持TreeShaking?
答:Vue2的声明式API不支持ES6的TreeSharking特性,Vue3的组合式API+SetUp语法糖能够很方便的支持该特性。
Vue3虚拟DOM的优化?
答:在Vue2中,每次更新diff,都是全量对比,Vue3则只对比带有标记的(Patch Flag ),这样大大减少了非动态内容的对比消耗。
Vue虚拟DOM详解?
答:由于DOM上的属性非常的多,如果我们直接操作DOM的话,会非常的消耗性能。为了解决这个问题,可以使用JS的计算性能来换取操作DOM所消耗的性能。通过JS在内存中生成一个AST节点树(抽象语法树),通过diff算法实现虚拟DOM与DOM的对比更新。
Vue响应式详解?
答:原生的JavaScript没有提供任何机制能做到对变量的直接追踪读写,进行实时更新,但是我们可以把变量包装到对象里,通过追踪对象属性的读写实现对应的效果。在 JavaScript 中有两种劫持 property 访问的方式:getter / setters 和 Proxies。Vue 2 使用 getter / setters 完全是出于支持旧版本浏览器的限制。而在 Vue 3 中则使用了 Proxy 来创建响应式对象,仅将 getter / setter 用于 ref。
Computed详解?
答:两种使用方式,第一种函数式,不支持对属性进行修改操作。第二种,对象形式,可以通过get/set函数实现属性的可写。
Computed和直接使用方法的区别?
答:Computed存在缓存的概念,如果计算属性的值不被改变,无论访问多少次计算属性,都不会触发getter函数的执行;而方法则总是会在渲染时执行函数。在一般的情况下,其实两者都是可以使用的,然而当遇到一些耗性能的计算属性时,Computed的缓存会带来明显的性能提升。
Computed的可读性?
答:Computed默认是只读的。当你尝试修改一个计算属性时,你会收到一个运行时警告。只在某些特殊场景中你可能才需要用到“可写”的属性,你可以通过同时提供 getter 和 setter 来创建,即使用对象的形式使用Computed。
监听详解?
答:watch和watchEffect。watch适合监听明确的数据源或者是依赖项。对于多个数据源或者依赖项watchEffect会更合适。另外,watchEffect不需要指定immediate: true,它默认会立即执行一次回调。简而言之,watch监听第一个明确的入参,watchEffect监听回调函数里面的所有数据源或者依赖项。
组件的生命周期详解?
答:Vue3的组合式API是没有 beforeCreate 和 created 这两个生命周期的。除此之外还有Mount、Update、Unmount
父子组件传参详解?
答:
父传子(Props):父组件通过v-bind绑定一个数据,然后子组件通过defineProps宏函数接受传过来的值,赋值给一个变量,通过变量.$name进行使用。(单向数据流,即数据不会逆传,只能有父组件更新传到子组件。你不应该在子组件中去更改一个 prop。若你这么做了,Vue 会在控制台上向你抛出警告)
子传父(自定义事件Emit):子组件通过defineEmits宏函数显示地声明一个自定义事件,宏函数返回的也是一个函数对象,在子组件中调用这个函数对象;父组件通过@事件名="父组件自定义的函数名" 来监听子组件中定义的自定义事件,在函数的入参中接收子组件传递的参数进行使用。(defineEmits()宏函数必须直接放置在 <script setup> 的顶级作用域下)
子组件暴露给父组件内部属性:子组件通过defineExpose宏函数暴露给父组件内部属性,父组件通过ref从子组件实例获取属性。
全局组件,局部组件,动态组件详解?
答:
全局组件:使用频率非常高的,在入口的main.js或者main.ts文件里,跟随在createApp(App) 后面,通过component()进行全局的引入。
局部组件:组件里import
动态组件:让多个组件使用同一个挂载点,并动态切换。例如,组件A引入了B、C两个组件,然后通过 <component :is="组件名"></component>将两个组件挂载到同一个挂载点,进行动态的切换。
插槽详解?
答:插槽就是子组件中的提供给父组件使用的一个占位符,用<slot></slot> 表示,父组件可以在这个占位符中填充任何模板代码,如 HTML、组件等,填充的内容会替换子组件的<slot></slot>标签。
依赖注入Provide/Inject详解?
答:provide 可以在祖先组件中指定我们想要提供给后代组件的数据或方法,而在任何后代组件中,我们都可以使用 inject 来接收 provide 提供的数据或方法。(后代组件是可以修改值的,如果不想后代组件改,父组件要用readonly()来包装值)
兄弟组件传参详解?
答:
①借助父组件传参,即让父组件充当桥梁,确定是比较麻烦
②Event Bus 发布订阅模式(defineEmit)(另外,有第三方的库可以用,Mitt)
小彩蛋。!!
自动引入插件:
安装:install unplugin-auto-import/vite
配置:import AutoImport from 'unplugin-auto-import/vite'
export default defineConfig({
plugins: [vue(),AutoImport({
imports:['vue'],
dts:"src/auto-import.d.ts"
})]
})
v-model详解?
答:v-model 其实是一个语法糖 通过props 和 emit组合而成的
Vue样式穿透详解?
答:
scoped原理:vue中的scoped 通过在DOM结构以及css样式上加唯一不重复的标记:data-v-hash的方式,以保证唯一(而这个工作是由过PostCSS转译实现的),达到样式私有化模块化的目的。
scoped也有问题:他在进行PostCss转化的时候把元素选择器默认放在了最后,有可能会导致样式出问题
解决: Vue 提供了样式穿透:deep() 他的作用就是用来改变 属性选择器的位置
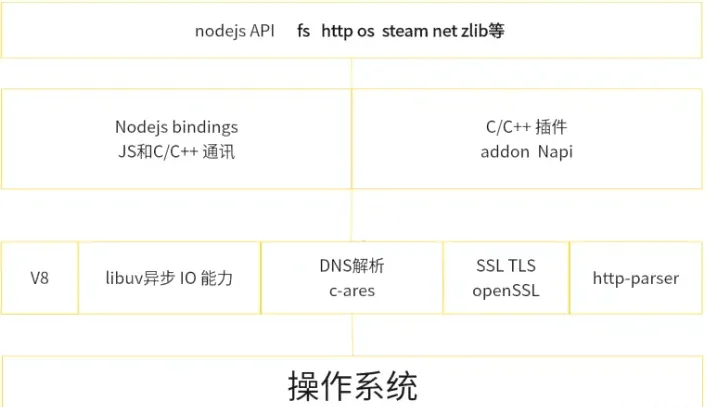
Node.js
概述
nodejs 并不是
JavaScript应用,也不是编程语言,因为编程语言使用的JavaScript,Nodejs是JavaScript的运行时。Nodejs是构建在V8引擎之上的,V8引擎是由C/C++编写的,因此我们的JavaSCript代码需要由C/C++转化后再执行。
NodeJs 使用异步 I/O 和事件驱动的设计理念,可以高效地处理大量并发请求,提供了非阻塞式 I/O 接口和事件循环机制,使得开发人员可以编写高性能、可扩展的应用程序,异步I/O最终都是由
libuv事件循环库去实现的。NodeJs 使用npm 作为包管理工具类似于python的pip,或者是java的Maven,目前npm拥有上百万个模块。 www.npmjs.com/
nodejs适合干一些IO密集型应用,不适合CPU密集型应用,nodejsIO依靠libuv有很强的处理能力,而CPU因为nodejs单线程原因,容易造成CPU占用率高,如果非要做CPU密集型应用,可以使用C++插件编写 或者nodejs提供的
cluster。(CPU密集型指的是图像的处理 或者音频处理需要大量数据结构 + 算法)
架构图
应用场景
我们常见的:Vue Angular React nuxtjs nextjs、web应用 epxress RPC gRPC 爬虫 网关层 、electron tauri、ionic React Native、webpack vite rollup gulp less scss postCss babel swc Jenkins docker 等等。。。。。。
安装(略)
Npm Package json
npm
是 Node.js 的包管理工具
npm 命令
npm init:初始化一个新的 npm 项目,创建 package.json 文件。npm install:安装一个包或一组包,并且会在当前目录存放一个node_modules。npm install <package-name>:安装指定的包。npm install <package-name> --save:安装指定的包,并将其添加到 package.json 文件中的依赖列表中。npm install <package-name> --save-dev:安装指定的包,并将其添加到 package.json 文件中的开发依赖列表中。npm install -g <package-name>:全局安装指定的包。npm update <package-name>:更新指定的包。npm uninstall <package-name>:卸载指定的包。npm run <script-name>:执行 package.json 文件中定义的脚本命令。npm search <keyword>:搜索 npm 库中包含指定关键字的包。npm info <package-name>:查看指定包的详细信息。npm list:列出当前项目中安装的所有包。npm outdated:列出当前项目中需要更新的包。npm audit:检查当前项目中的依赖项是否存在安全漏洞。npm publish:发布自己开发的包到 npm 库中。npm login:登录到 npm 账户。npm logout:注销当前 npm 账户。npm link: 将本地模块链接到全局的node_modules目录下npm config list用于列出所有的 npm 配置信息。执行该命令可以查看当前系统和用户级别的所有 npm 配置信息,以及当前项目的配置信息(如果在项目目录下执行该命令)npm get registry用于获取当前 npm 配置中的 registry 配置项的值。registry 配置项用于指定 npm 包的下载地址,如果未指定,则默认使用 npm 官方的包注册表地址npm set registrynpm config set registry <registry-url>命令,将 registry 配置项的值修改为指定的<registry-url>地址
Package json
执行npm init 便可以初始化一个package.json
name:项目名称,必须是唯一的字符串,通常采用小写字母和连字符的组合。version:项目版本号,通常采用语义化版本号规范。description:项目描述。main:项目的主入口文件路径,通常是一个 JavaScript 文件。keywords:项目的关键字列表,方便他人搜索和发现该项目。author:项目作者的信息,包括姓名、邮箱、网址等。license:项目的许可证类型,可以是自定义的许可证类型或者常见的开源许可证(如 MIT、Apache 等)。dependencies:项目所依赖的包的列表,这些包会在项目运行时自动安装。devDependencies:项目开发过程中所需要的包的列表,这些包不会随项目一起发布,而是只在开发时使用。peerDependencies:项目的同级依赖,即项目所需要的模块被其他模块所依赖。scripts:定义了一些脚本命令,比如启动项目、运行测试等。repository:项目代码仓库的信息,包括类型、网址等。bugs:项目的 bug 报告地址。homepage:项目的官方网站地址或者文档地址。
Npm install 原理
package-lock.json 的作用
可以锁定版本记录依赖树详细信息:
version 该参数指定了当前包的版本号
resolved 该参数指定了当前包的下载地址
integrity 用于验证包的完整性
dev 该参数指定了当前包是一个开发依赖包
bin 该参数指定了当前包中可执行文件的路径和名称
engines 该参数指定了当前包所依赖的Node.js版本范围
但是,除此之外package-lock.json 还帮我们做了缓存,他会通过 name + version + integrity 信息生成一个唯一的key,这个key能找到对应的index-v5 下的缓存记录 也就是npm cache 文件夹下的,如果发现有缓存记录,就会找到tar包的hash值,然后将对应的二进制文件解压到node_modeules。
Npm run 原理
读取package json 的scripts 对应的脚本命令(dev:vite),vite是个可执行脚本,他的查找规则是:
先从当前项目的node_modules/.bin去查找可执行命令vite
如果没找到就去全局的node_modules 去找可执行命令vite
如果还没找到就去环境变量查找
再找不到就进行报错
npm 生命周期
"predev": "node prev.js",
"dev": "node index.js",
"postdev": "node post.js"执行 npm run dev 命令的时候 predev 会自动执行 他的生命周期是在dev之前执行,然后执行dev命令,再然后执行postdev,也就是dev之后执行运用场景例如npm run build 可以在打包之后删除dist目录等等
模块化
Nodejs 模块化规范遵循两套一 套CommonJS规范另一套esm规范
CommonJS 规范
引入模块(require)支持四种格式
支持引入内置模块例如
httposfschild_process等nodejs内置模块支持引入第三方模块
expressmd5koa等支持引入自己编写的模块 ./ ../ 等
支持引入addon C++扩展模块 .node文件
const fs = require('node:fs'); // 导入核心模块
const express = require('express'); // 导入 node_modules 目录下的模块
const myModule = require('./myModule.js'); // 导入相对路径下的模块
const nodeModule = require('./myModule.node'); // 导入扩展模块
导出模块exports 和 module.exports
module.exports = {
hello: function() {
console.log('Hello, world!');
}
};如果不想导出对象直接导出值
module.exports = 123ESM模块规范
引入模块 import 必须写在头部
import fs from 'node:fs'加载模块的整体对象
import * as all from 'xxx.js'动态导入模块
import静态加载不支持掺杂在逻辑中如果想动态加载请使用import函数模式
if(true){
import('./test.js').then()
}模块导出
//导出一个默认对象 default只能有一个不可重复export default
export default {
name: 'test',
}
//导出变量
export const a = 1Cjs 和 ESM 的区别
Cjs是基于运行时的同步加载,esm是基于编译时的异步加载
Cjs是可以修改值的,esm值并且不可修改(可读的)
Cjs不可以tree shaking,esm支持tree shaking
commonjs中顶层的this指向这个模块本身,而ES6中顶层this指向undefined
全局变量
__dirname 它表示当前模块的所在目录的绝对路径
__filename 它表示当前模块文件的绝对路径,包括文件名和文件扩展名
require module 引入模块和模块导出
process 可用于监控进程、设置信号处理、发送IPC消息等
Buffer Buffer类在处理文件、网络通信、加密和解密等操作中非常有用,尤其是在需要处理二进制数据时
CSR SSR SEO
CSR 和 SSR 区别:
页面加载方式:
CSR:在 CSR 中,服务器返回一个初始的 HTML 页面,然后浏览器下载并执行 JavaScript 文件,JavaScript 负责动态生成并更新页面内容。这意味着初始页面加载时,内容较少,页面结构和样式可能存在一定的延迟。
SSR:在 SSR 中,服务器在返回给浏览器之前,会预先在服务器端生成完整的 HTML 页面,包含了初始的页面内容。浏览器接收到的是已经渲染好的 HTML 页面,因此初始加载的速度较快。
内容生成和渲染:
CSR:在 CSR 中,页面的内容生成和渲染是由客户端的 JavaScript 脚本负责的。当数据变化时,JavaScript 会重新生成并更新 DOM,从而实现内容的动态变化。这种方式使得前端开发更加灵活,可以创建复杂的交互和动画效果。
SSR:在 SSR 中,服务器在渲染页面时会执行应用程序的代码,并生成最终的 HTML 页面。这意味着页面的初始内容是由服务器生成的,对于一些静态或少变的内容,可以提供更好的首次加载性能。
用户交互和体验:
CSR:在 CSR 中,一旦初始页面加载完成,后续的用户交互通常是通过 AJAX 或 WebSocket 与服务器进行数据交互,然后通过 JavaScript 更新页面内容。这种方式可以提供更快的页面切换和响应速度,但对于搜索引擎爬虫和 SEO(搜索引擎优化)来说,可能需要一些额外的处理。
SSR:在 SSR 中,由于页面的初始内容是由服务器生成的,因此用户交互可以直接在服务器上执行,然后服务器返回更新后的页面。这样可以提供更好的首次加载性能和对搜索引擎友好的内容。
SEO(搜索引擎优化)
CSR应用对SEO并不是很友好,因为在首次加载的时候获取HTML 信息较少 搜索引擎爬虫可能无法获取完整的页面内容,而SSR就不一样了 由于 SSR 在服务器端预先生成完整的 HTML 页面,搜索引擎爬虫可以直接获取到完整的页面内容。这有助于搜索引擎正确理解和评估页面的内容。
哪些网站适合做CSR 哪些适合做SSR:
CSR 应用例如 ToB 后台管理系统 大屏可视化 都可以采用CSR渲染不需要很高的SEO支持
SSR 应用例如 内容密集型应用大部分是ToC 新闻网站 ,博客网站,电子商务,门户网站需要更高的SEO支持